
It was so hot and humid. It was also extremely crowded. There was barely enough room to turn around. And as usual, the idiots to the front and sides of me were either too high, too drunk, or too stupid to realize there wasn’t enough room to dance without stepping on or spilling beer all over the people next to them. I waited. And with my mind’s eye, I watched each bead of sweat travel from the nape of my neck and down my back. Did I mention it was hot?
It was August 1, 2003. Hundreds of us had packed into Bogart’s, a tiny little club in Cincinnati, OH, to see The Flaming Lips perform. We had endured hours of opening acts. When the Lips finally took the stage, the crowd tapped into its energy reserves. And it was amazing! What I had expected to be a plain ole rock show transformed into a carnival of blissful insanity complete with dancing animals, fake blood, giant balls, and an endless supply of confetti.
At some point during the show (I REALLY wish I could remember which song), Wayne Coyne began playing a theremin. Until that point, I had only ever seen theremins used for spooky, outer-spacey effects. A mood piece. I had never seen or heard one used to play an actual song, especially with a band. (Correction: Apparently that little whistle sound in the Beach Boys’ hit “Good Vibrations” is a theremin. I had no idea.) As Coyne’s arms and hands waved around in the air, producing sounds that crossed the line between melodic and psychotic, I was captivated.
I promised myself I’d try to play one someday. Unfortunately, this project is the closest I’ve gotten. 🙂
What The Heck Is A Theremin?

Source: https://www.pinterest.com/darinblass/vintage/
A traditional theremin looks like a box with one antenna popping out of the top and one out of the side. The thereminist (yes, that’s really what they’re called) moves their hands back and forth, away and towards the antennas. The proximity to one antenna controls the pitch of the sound that’s produced. The proximity to the other antenna controls the volume. The whole setup works by varying capacitance that controls a variable-pitch oscillator, which is really the source of all those crazy sounds.
Building a Cheap “Light Theremin”
A number of “light theremin” projects have appeared in my RSS feed over the past few years. And I had always intended to build one, but only recently did I actually get around to it. What follows is my take on the basic “light theremin”, as inspired by a version from Make Magazine.
Keep in mind that a “light theremin” is not a real theremin. Instead of varying capacitance, it varies the resistance of a photoresistor. And instead of an oscillator that produces pleasant sinusoidal sounds, it uses a 555 timer to generate square waves (PWM).
Below is the parts list and schematic if you’re interested. This project can be assembled in less than 30 minutes, if you’ve got the parts. And if you don’t have the parts, they can all be found on EBay for cheap.
Parts List
- 1 555 Timer
- 2 Photoresistors (Buy an assortment and try different ones)
- 1 10 KOhm Resistor
- 1 1 MOhm Resistor
- 2 0.22uF Capacitors
- 1 100uF Capacitor
- 1 Speaker (Mine is a 30mm .5 Watt 8 Ohm speaker I found on EBay)
- Optional: Assorted photodiodes
- Optional: Potentiometer
Schematic
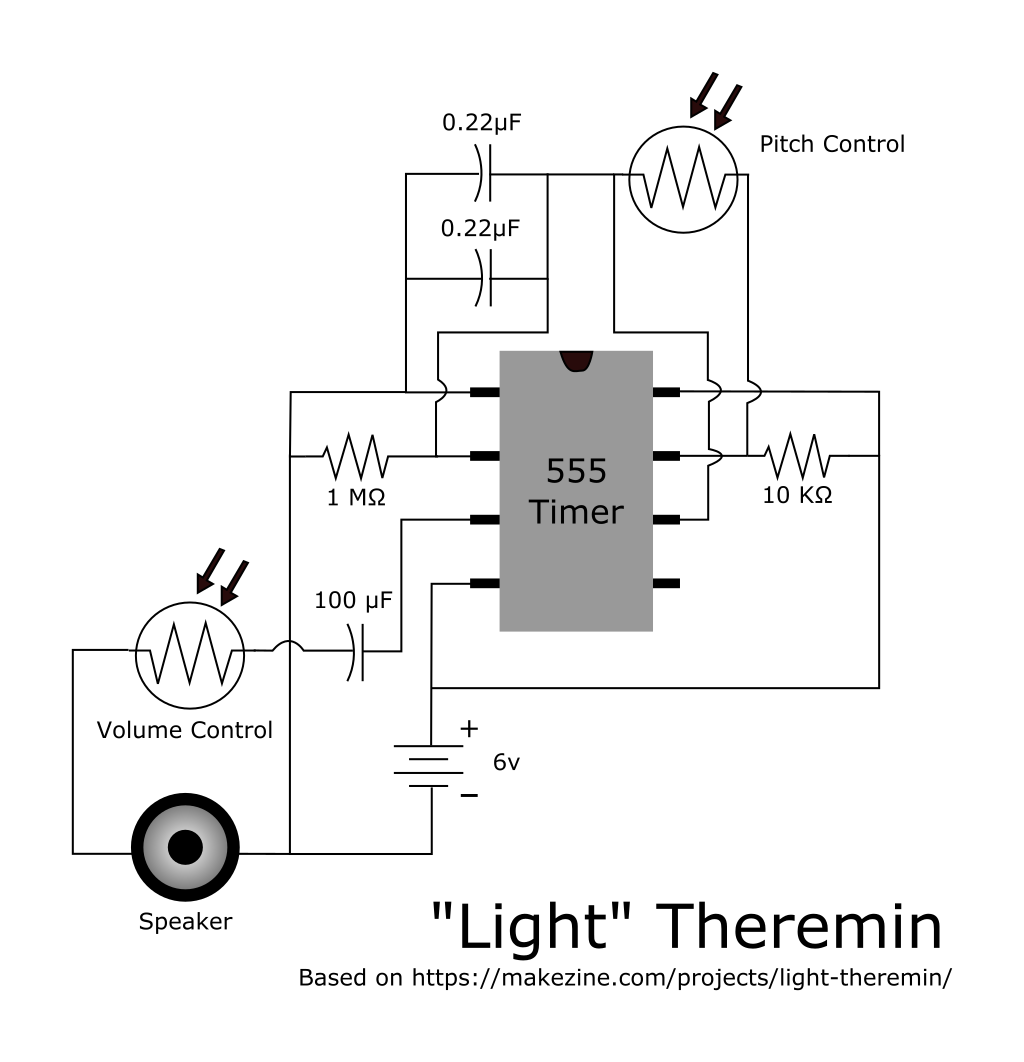
The schematic calls for 6V DC. You can run it off of less. But as the voltage decreases, so does the volume.
Also, there are two photoresistors shown in the schematic. I had problems finding a photoresistor with a low enough resistance to use as an effective volume control. In the video below, I just used a potentiometer I had on hand. A photodiode might actually work better. At the time of this writing, I didn’t have any so I couldn’t try it.
Conclusion
If you have aspirations of building a performance instrument, you should probably look elsewhere. Light conditions vary from place to place. The response of this circuit can be unpredictable, even in the same room at different times of the day. Also, the audio produced is basically a square wave, which is the most obnoxious of all the basic oscillator types.
But if you’re looking for a fun project to do in an afternoon, this one is a lot of fun. Especially if you enjoy annoying everyone in your immediate vicinity. 🙂
-Shane

